ldm的VQGAN还在跑,先来看下huggingface现有的diffusion model的实现框架.
diffusion model(ddpm)
install
首先安装和import 1
2
3!pip install diffusers["torch"] transformers
from diffusers import DDPMPipeline
pipline
pipline简洁代码 1
2
3ddpm = DDPMPipeline.from_pretrained("google/ddpm-cat-256", use_safetensors=True).to("cuda")
image = ddpm(num_inference_steps=30).images[0]
image
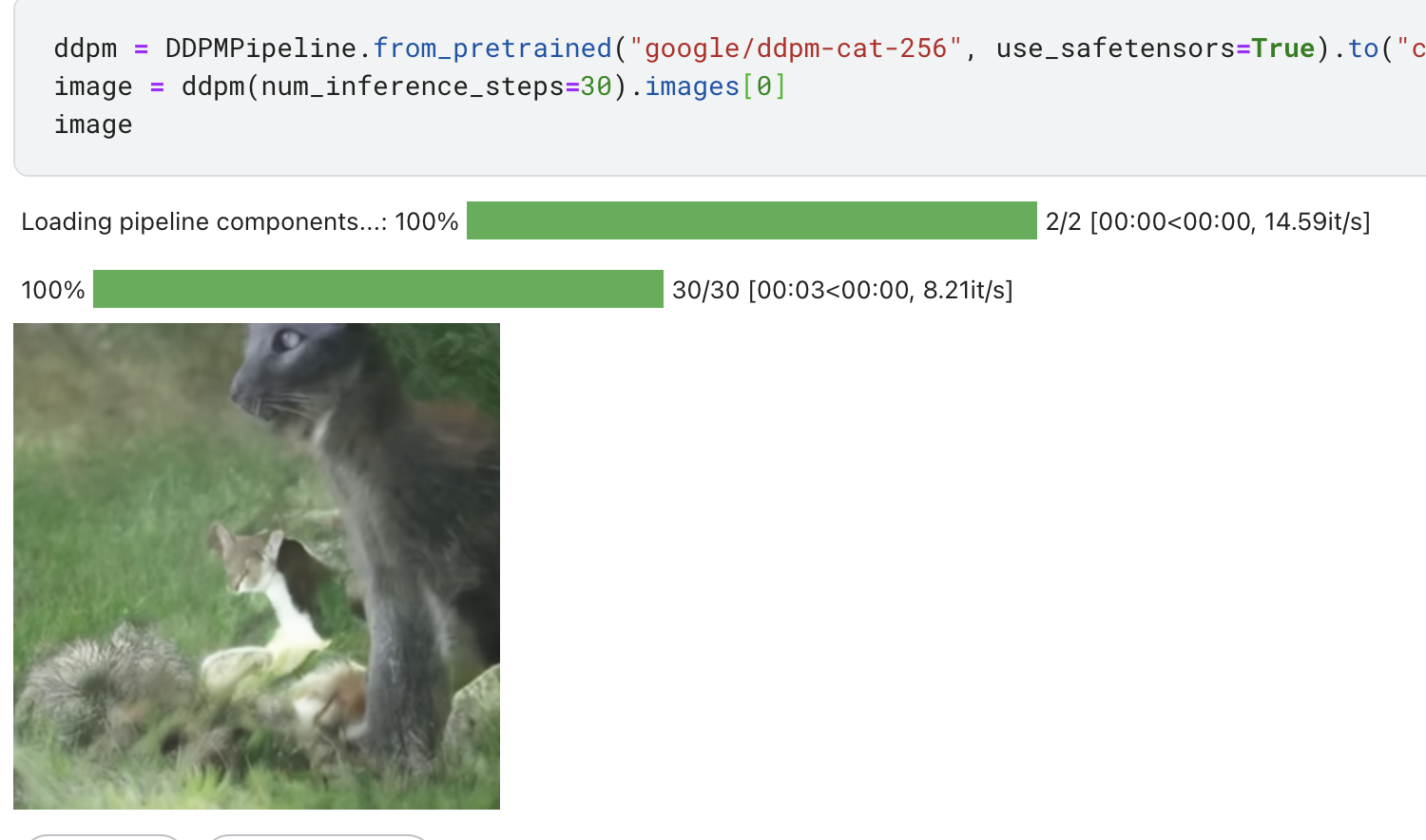
效果其实一般.
内部细节
还是和前面看的ddpm一样, Unet加上一个scheduler.
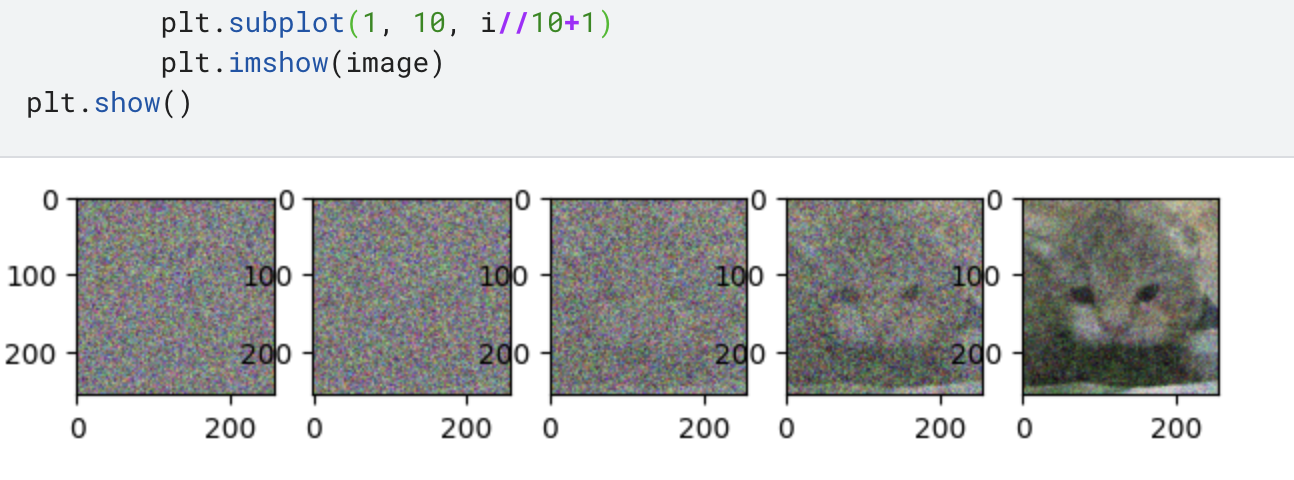
对生成结果进行绘图得到以下结果. 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26from PIL import Image
import numpy as np
from matplotlib import pyplot as plt
import torch
from diffusers import DDPMScheduler, UNet2DModel
scheduler = DDPMScheduler.from_pretrained('google/ddpm-cat-256')
model = UNet2DModel.from_pretrained('google/ddpm-cat-256', use_safetensors=True).to('cuda')
scheduler.set_timesteps(50)
noice = torch.randn((1,3,model.config.sample_size,model.config.sample_size), device='cuda')
img_index = 0
fig = plt.figure(figsize=(15,15))
for i, t in enumerate(scheduler.timesteps):
with torch.no_grad():
noisy_residual = model(noice, t).sample
previous_noisy_sample = scheduler.step(noisy_residual, t, noice).prev_sample
noice = previous_noisy_sample
if i % 10 == 0:
image = (noice / 2 + 0.5).clamp(0, 1).squeeze()
image = (image.permute(1, 2, 0) * 255).round().to(torch.uint8).cpu().numpy()
image = Image.fromarray(image)
plt.subplot(1, 10, i//10+1)
plt.imshow(image)
plt.show()
stable diffusion
pipline
有stable diffusion1.5, stable diffusion XL等等 1
2
3
4
5
6
7
8
9from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
generator = torch.Generator("cuda").manual_seed(31)
image = pipeline("a bowl of cats, cute", generator=generator).images[0]
image

PNDM(Pseudo Numerical Methods for Diffusion Models on Manifolds)
scheduler也是有不少的,从ddpm到ddim到pndm,具体可以看Note on Variants of Diffusion Scheduler, DDPM DDIM PNDM.
大概来说就是ddpm基于markov,ddim是deterministic且对back process做了优化. pndm是对ddim做出了微分方程求解层面的优化.
不过官方给的说法是stable diffusion默认用pndm,那我们就展现一下换scheduler有多简单,于是用的就是UniPCMultistepScheduler.
load from pretrained
这里区别于前面的UNet,这里的UNet是conditional. 然后encoder用的AutoencoderKL.
1 | from PIL import Image |
text processing
文本方面就是先tokenize然后embedding,然后取padding token再做一次embedding最后concat
1 | # text processing |
train
这里官方的generator会出问题,用cuda的话记得用torch.cuda.manual_seed
然后思路很简单, 直接check vae的downsample数,然后对维度直接进行调整,生成latent space的random input.
然后unet里面传入text embedding作为hidden state. 然后这里guidance我不是很理解,大概是unet默认同时传出conditional和unconditional的result,然后这里手动做调整?
1 | from tqdm.auto import tqdm |
show result
1 | latents = 1 / 0.18215 * latents |
