import bs4 from langchain import hub from langchain_chroma import Chroma from langchain_community.document_loaders import WebBaseLoader from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough from langchain_community.llms import Ollama from langchain_community.chat_models.ollama import ChatOllama from langchain_community.embeddings import OllamaEmbeddings from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load, chunk and index the contents of the blog. loader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), bs_kwargs=dict( parse_only=bs4.SoupStrainer( class_=("post-content", "post-title", "post-header") ) ), ) docs = loader.load()
# split and save to chroma text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) splits = text_splitter.split_documents(docs) vectorstore = Chroma.from_documents(documents=splits, embedding=OllamaEmbeddings(model="nomic-embed-text"))
# Retrieve and generate using the relevant snippets of the blog. retriever = vectorstore.as_retriever() prompt = hub.pull("rlm/rag-prompt") llm = Ollama(model="llama3", keep_alive=-1)
defformat_docs(docs): return"\n\n".join(doc.page_content for doc in docs)
Given a chat history and the latest user question which might
reference context in the chat history, formulate a standalone question
which can be understood without the chat history. Do NOT answer the
question, just reformulate it if needed and otherwise
return it as is.
prompt = MessagesPlaceholder("history", optional=True) prompt.format_messages() # returns empty list []
prompt.format_messages( history=[ ("system", "You are an AI assistant."), ("human", "Hello!"), ] ) # -> [ # SystemMessage(content="You are an AI assistant."), # HumanMessage(content="Hello!"), # ]
retrieve_documents: RetrieverOutputLike = RunnableBranch( ( # Both empty string and empty list evaluate to False lambda x: not x.get("chat_history", False), # If no chat history, then we just pass input to retriever (lambda x: x["input"]) | retriever, ), # If chat history, then we pass inputs to LLM chain, then to retriever prompt | llm | StrOutputParser() | retriever, ).with_config(run_name="chat_retriever_chain")
实际代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
from langchain.chains import create_history_aware_retriever from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
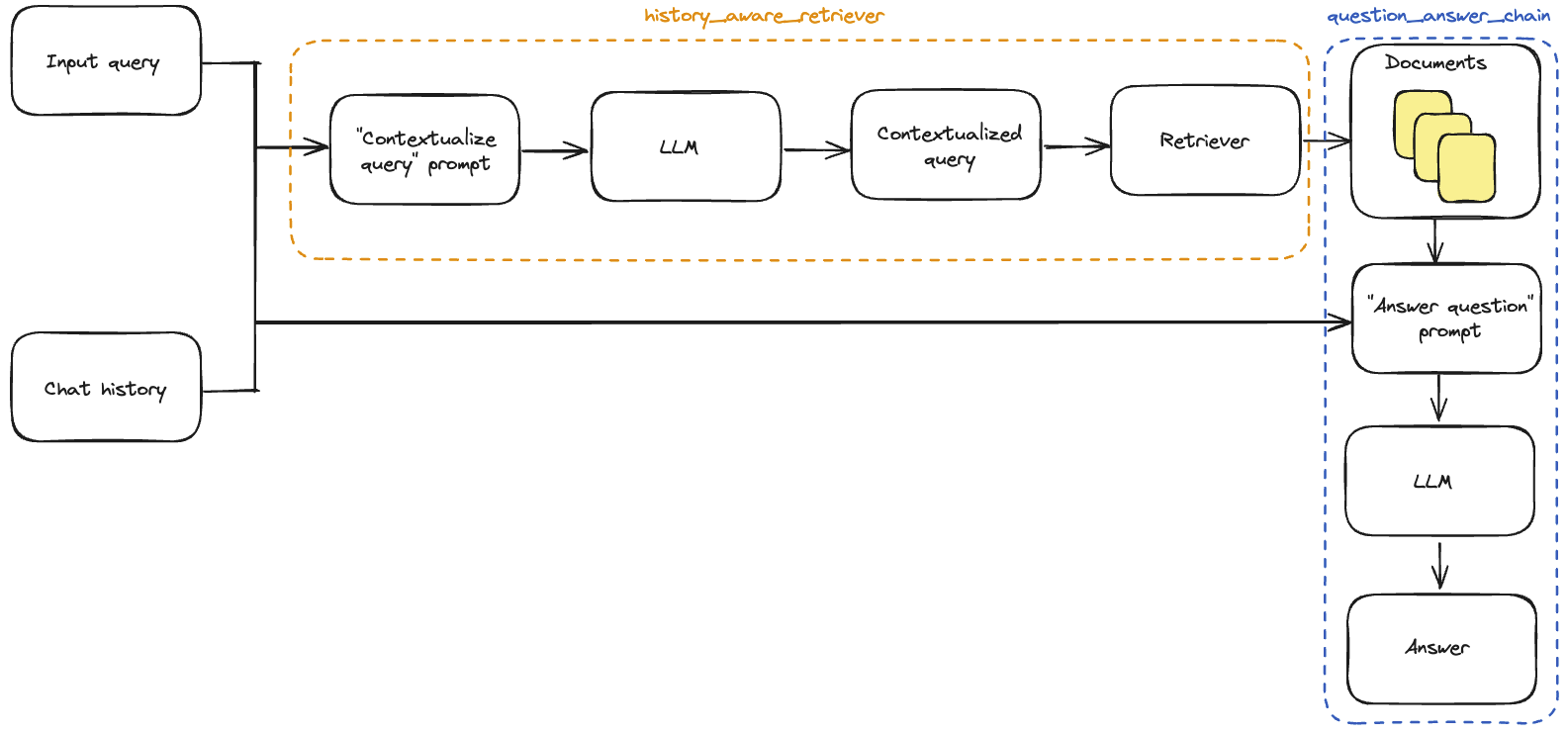
contextualize_q_system_prompt = """Given a chat history and the latest user question \ which might reference context in the chat history, formulate a standalone question \ which can be understood without the chat history. Do NOT answer the question, \ just reformulate it if needed and otherwise return it as is.""" contextualize_q_prompt = ChatPromptTemplate.from_messages( [ ("system", contextualize_q_system_prompt), MessagesPlaceholder("chat_history"), ("human", "{input}"), ] ) history_aware_retriever = create_history_aware_retriever( llm, retriever, contextualize_q_prompt )
from langchain.chains import create_retrieval_chain from langchain.chains.combine_documents import create_stuff_documents_chain
qa_system_prompt = """You are an assistant for question-answering tasks. \ Use the following pieces of retrieved context to answer the question. \ If you don't know the answer, just say that you don't know. \ Use three sentences maximum and keep the answer concise.\ {context}""" qa_prompt = ChatPromptTemplate.from_messages( [ ("system", qa_system_prompt), MessagesPlaceholder("chat_history"), ("human", "{input}"), ] )
RunnableWithMessageHistory:
Wrapper for an LCEL chain and a BaseChatMessageHistory that handles
injecting chat history into inputs and updating it after each
invocation.
from langchain_core.chat_history import BaseChatMessageHistory from langchain_community.chat_message_histories import ChatMessageHistory from langchain_core.runnables.history import RunnableWithMessageHistory ### Statefully manage chat history ### store = {}
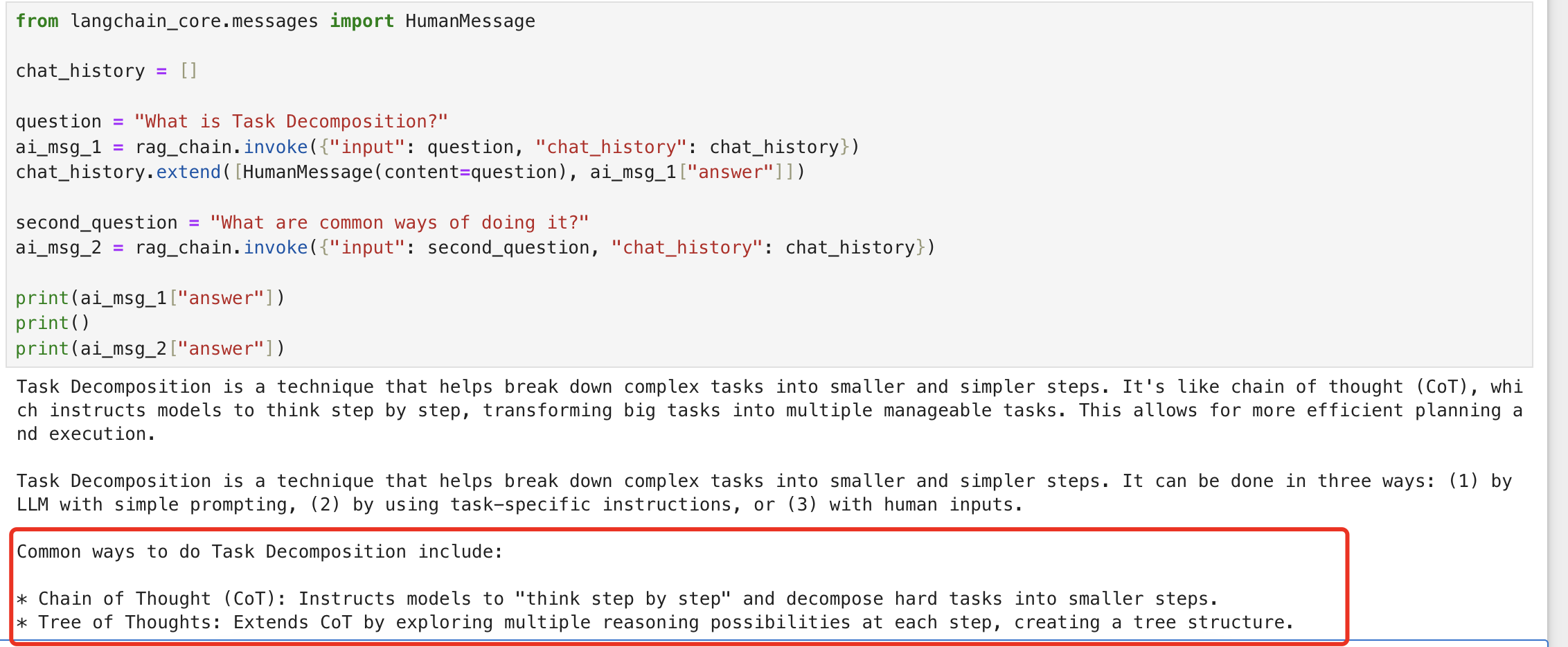
conversational_rag_chain.invoke( {"input": "What is Task Decomposition?"}, config={ "configurable": {"session_id": "abc123"} }, # constructs a key "abc123" in `store`. )["answer"] # "Task decomposition is a technique that breaks down complex tasks into smaller and simpler steps. It involves decomposing big tasks into multiple manageable tasks, making it easier to understand the model's thinking process and interpret the results. This approach is often used in prompting techniques like Chain of Thought (CoT) to enhance model performance on complex tasks."
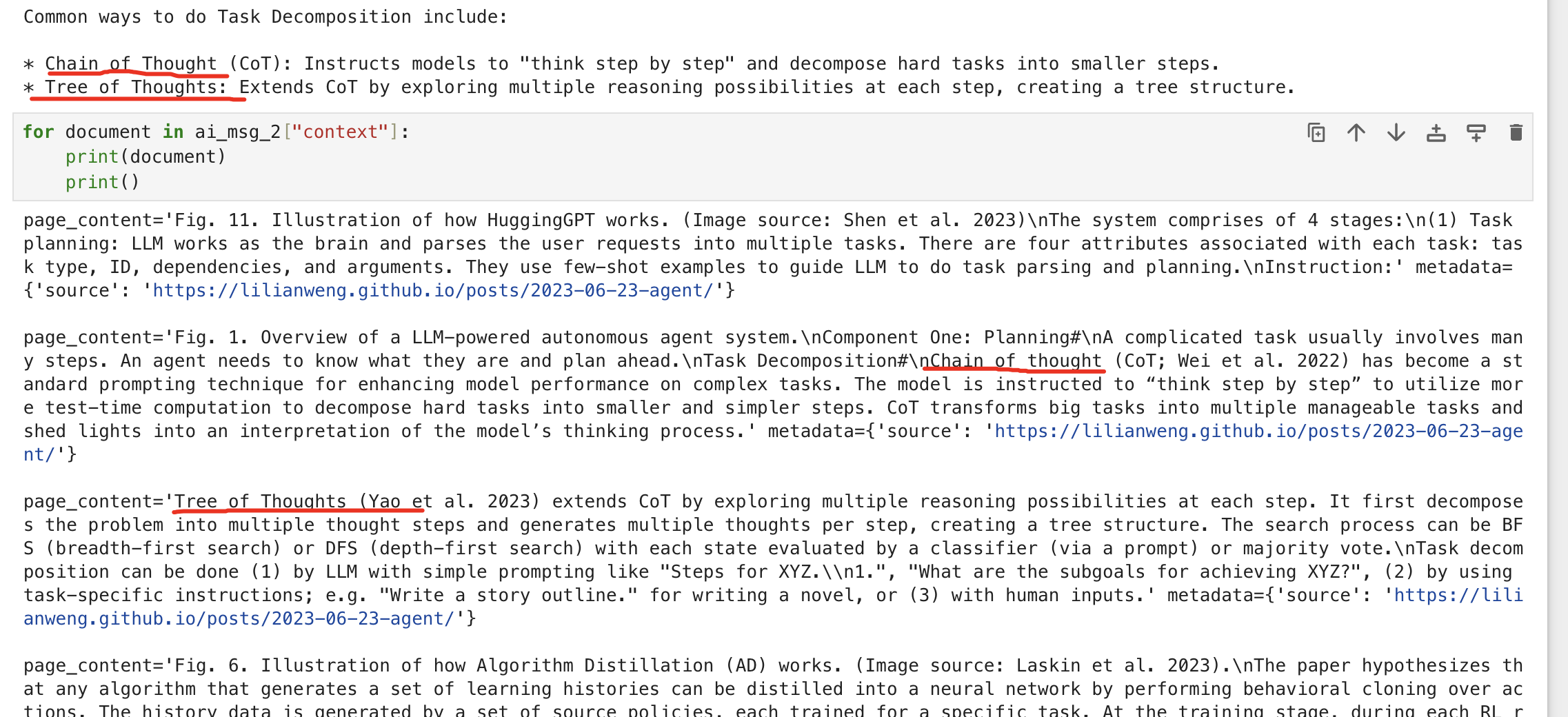
conversational_rag_chain.invoke( {"input": "What are common ways of doing it?"}, config={"configurable": {"session_id": "abc123"}}, )["answer"] # 'Task decomposition can be achieved through various methods, including:\n\n* Chain of Thought (CoT): Instructing the model to "think step by step" to decompose hard tasks into smaller and simpler steps.\n* Behavioral cloning over actions: Using a set of source policies trained for specific tasks to generate learning histories and distill them into a neural network.\n\nI don\'t know about other common ways.'