MX = 1_000_001 LPF = [i for i inrange(MX)] LPF[0] = LPF[1] = 0 prime = [] for i inrange(2, MX): if LPF[i] == i: prime.append(i) for p in prime: if p * i >= MX: break LPF[p*i] = p if i % p == 0: break
classSolution: defminOperations(self, nums: List[int]) -> int: prev = nums[-1] ans = 0 for x inreversed(nums[:-1]): curr = x if x > prev: curr = LPF[x] if curr > prev: return -1 ans += 1 prev = curr return ans
3327. 判断 DFS
字符串是否是回文串
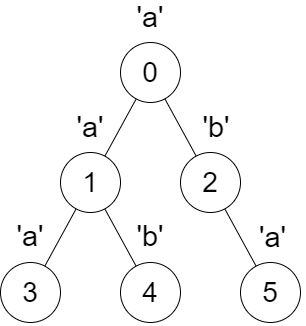
给你一棵 n 个节点的树,树的根节点为 0
,n 个节点的编号为 0 到
n - 1 。这棵树用一个长度为 n 的数组
parent 表示,其中 parent[i] 是节点
i 的父节点。由于节点 0
是根节点,所以 parent[0] == -1 。
给你一个长度为 n 的字符串
s ,其中 s[i] 是节点
i 对应的字符。
一开始你有一个空字符串 dfsStr ,定义一个递归函数 dfs(int x) ,它的输入是节点
x ,并依次执行以下操作:
按照 节点编号升序 遍历
x 的所有孩子节点
y ,并调用 dfs(y) 。
将 字符
s[x] 添加到字符串 dfsStr 的末尾。
注意,所有递归函数 dfs 都共享全局变量
dfsStr 。
你需要求出一个长度为
n 的布尔数组 answer ,对于 0 到
n - 1 的每一个下标
i ,你需要执行以下操作:
classSolution: deffindAnswer(self, parent: List[int], s: str) -> List[bool]: n = len(parent) tree = [[] for _ inrange(n)] for i inrange(1, n): tree[parent[i]].append(i)
dfsStr = [''] * n nodes = [[0,0] for _ inrange(n)] time = 0 defdfs(x): nonlocal time nodes[x][0] = time for y in tree[x]: dfs(y) dfsStr[time] = s[x] time += 1 nodes[x][1] = time dfs(0)
t = '#'.join(['^'] + dfsStr + ['$']) f = [0] * (len(t) - 2) f[1] = 1 center=r=0 for i inrange(2, len(f)): hl = 1 if i < r: hl = min(f[2*center - i], r - i) while t[i - hl] == t[i+hl]: hl += 1 center, r = i, i + hl f[i] = hl defisPalindro(l, r): return f[l+r+1] > r - l return [isPalindro(l,r) for l,r in nodes]
10月13周赛
3320. 统计能获胜的出招序列数
Alice 和 Bob 正在玩一个幻想战斗游戏,游戏共有 n
回合,每回合双方各自都会召唤一个魔法生物:火龙(F)、水蛇(W)或地精(E)。每回合中,双方
同时 召唤魔法生物,并根据以下规则得分:
如果一方召唤火龙而另一方召唤地精,召唤 火龙
的玩家将获得一分。
如果一方召唤水蛇而另一方召唤火龙,召唤 水蛇
的玩家将获得一分。
如果一方召唤地精而另一方召唤水蛇,召唤 地精
的玩家将获得一分。
如果双方召唤相同的生物,那么两个玩家都不会获得分数。
给你一个字符串 s,包含 n 个字符
'F'、'W' 和 'E',代表 Alice
每回合召唤的生物序列:
如果 s[i] == 'F',Alice 召唤火龙。
如果 s[i] == 'W',Alice 召唤水蛇。
如果 s[i] == 'E',Alice 召唤地精。
Bob 的出招序列未知,但保证 Bob
不会在连续两个回合中召唤相同的生物。如果在 n 轮后 Bob
获得的总分 严格大于 Alice 的总分,则 Bob 战胜
Alice。
返回 Bob 可以用来战胜 Alice 的不同出招序列的数量。
由于答案可能非常大,请返回答案对 109 + 7取余 后的结果。
示例 1:
输入: s = "FFF"
输出: 3
解释:
Bob 可以通过以下 3 种出招序列战胜
Alice:"WFW"、"FWF" 或
"WEW"。注意,其他如 "WWE" 或
"EWW" 的出招序列是无效的,因为 Bob
不能在连续两个回合中使用相同的生物。
示例 2:
输入: s = "FWEFW"
输出: 18
解释:
Bob 可以通过以下出招序列战胜
Alice:"FWFWF"、"FWFWE"、"FWEFE"、"FWEWE"、"FEFWF"、"FEFWE"、"FEFEW"、"FEWFE"、"WFEFE"、"WFEWE"、"WEFWF"、"WEFWE"、"WEFEF"、"WEFEW"、"WEWFW"、"WEWFE"、"EWFWE"
或 "EWEWE"。
from sortedcontainers import SortedList classSolution: deffindXSum(self, nums: List[int], k: int, x: int) -> List[int]: sl = SortedList(key=lambda x:(x[1],x[0])) d = defaultdict(int) ans = [] for i inrange(k): d[nums[i]] += 1 for k_, v_ in d.items(): sl.add((k_,v_)) sm = sum(a*b for a,b in sl[-x:]) ans.append(sm) for i inrange(k, len(nums)): if nums[i] != nums[i-k]: sl.discard((nums[i-k], d[nums[i-k]])) sl.add((nums[i-k], d[nums[i-k]]-1)) sl.discard((nums[i], d[nums[i]])) sl.add((nums[i], d[nums[i]]+1)) d[nums[i]] += 1 d[nums[i-k]] -= 1 sm = sum(a*b for a,b in sl[-x:]) ans.append(sm) else: ans.append(sm) return ans
classSolution: defmaxRemovals(self, source: str, pattern: str, targetIndices: List[int]) -> int: # i 表示 source 的idx # j 表示 pattern 的idx st = set(targetIndices) m = len(source) n = len(pattern) @cache defdfs(i, j): if j < 0: return bisect_left(targetIndices, i+1) if i < j: returnfloat('-inf') res = float('-inf') if i in st: if source[i] == pattern[j]: # not remove res = max(res, dfs(i-1, j-1)) # remove res = max(res, dfs(i-1, j)+1) else: if source[i] == pattern[j]: res = max(res, dfs(i-1, j-1)) else: res = max(res, dfs(i-1, j)) return res ans = dfs(m-1, n-1) return ans
贴个灵神的递推解, 内存只有16M
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defmaxRemovals(self, source: str, pattern: str, targetIndices: List[int]) -> int: m = len(pattern) f = [0] + [-inf] * m k = 0 for i, x inenumerate(source): if k < len(targetIndices) and targetIndices[k] < i: k += 1 is_del = 1if k < len(targetIndices) and targetIndices[k] == i else0 for j inrange(min(i, m - 1), -1, -1): f[j + 1] += is_del if x == pattern[j] and f[j] > f[j + 1]: f[j + 1] = f[j] f[0] += is_del return f[m]
3317. 安排活动的方案数
给你三个整数 n ,x 和 y 。
一个活动总共有
n 位表演者。每一位表演者会 被安排 到
x 个节目之一,有可能有节目
没有 任何表演者。
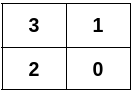
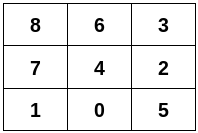
classSolution: defconstructGridLayout(self, n: int, edges: List[List[int]]) -> List[List[int]]: d = defaultdict(set) for u, v in edges: d[u].add(v) d[v].add(u)
row = [] count = 4 corner = None for k, v in d.items(): iflen(v) < count: corner = k count = len(v) row.append(corner) node = corner while1: min_v = 4 min_k = None for nei in d[node]: iflen(d[nei]) < min_v: min_k = nei min_v = len(d[nei]) if min_v > count: row.append(min_k) d[node] -= {min_k} d[min_k] -= {node} else: row.append(min_k) d[node] -= {min_k} d[min_k] -= {node} break node = min_k
row_len = len(row) m = n // row_len if m == 1: return [row] matrix = [[] for _ inrange(m)] matrix[0] = row for i inrange(1, m): for j inrange(row_len): upper = matrix[i - 1][j] curr = d[upper].pop() matrix[i].append(curr) d[curr] -= {upper} if j != 0: d[matrix[i][j - 1]] -= {matrix[i][j]} d[matrix[i][j]] -= {matrix[i][j - 1]} return matrix
3312. 查询排序后的最大公约数
给你一个长度为
n 的整数数组 nums 和一个整数数组 queries 。
gcdPairs 表示数组 nums 中所有满足
0 <= i < j < n 的数对
(nums[i], nums[j])
的最大公约数升序 排列构成的数组。
classSolution: defkthCharacter(self, k: int, operations: List[int]) -> str: inc = 0 for i inrange((k-1).bit_length()-1,-1,-1): v = 1 << i if k > v: inc += operations[i] k -= v return ascii_lowercase[inc % 26]
classSolution: defvalidSequence(self, word1: str, word2: str) -> List[int]: m = len(word1) n = len(word2) @cache defgreedy(i, j): if j == n: return [] if i == m: returnNone ans = [] while i != m: if word1[i] == word2[j]: ans.append(i) j += 1 if j == n: return ans i += 1 returnNone
w1 = 0 w2 = 0 ans = [] while w1 != m and w2 != n: if word1[w1] == word2[w2]: w2 += 1 ans.append(w1) if w2 == n: return ans else: check = greedy(w1 + 1, w2 + 1) if check isnotNone: return ans + [w1] + check w1 += 1 return []
classSolution: defz_func(self, s): n = len(s) z = [0] * n l = r = 0 for i inrange(1, n): if i <= r: z[i] = min(z[i-l], r-i+1) while i + z[i] < n and s[z[i]] == s[i+z[i]]: l, r = i, i + z[i] z[i] += 1 return z
defminStartingIndex(self, s: str, pattern: str) -> int: prez = self.z_func(pattern + s) suf_z = self.z_func(pattern[::-1] + s[::-1]) suf_z.reverse() m = len(pattern) for i inrange(m, len(s)+1): if prez[i] + suf_z[i-1] >= m - 1: return i - m return -1
classSolution: defminStartingIndex(self, s: str, pattern: str) -> int: deffind(start, pattern): n = len(pattern) if n == 1: return start m, max_ans = n >> 1, len(s) - n left, right = pattern[:m], pattern[m:] stack = [(start, True, True), (start, True, False)] ans, flag = max_ans + 1, False while stack and stack[-1][0] < ans: start, str_find, keep_left = stack.pop() if str_find: if keep_left: i = s.find(left, start) else: i = s.find(right, start + m) - m else: flag = True if keep_left: i = find(start + m, right) - m else: i = find(start, left) if i < 0or i >= ans: continue if i == start and flag: ans = i continue t = (i, not str_find, keep_left) if stack and stack[0] < t: t, stack[0] = stack[0], t stack.append(t) return -1if ans > max_ans else ans return find(0, pattern)
9月22周赛
3298.
统计重新排列后包含另一个字符串的子字符串数目 II
给你两个字符串 word1 和 word2 。
如果一个字符串
x 重新排列后,word2 是重排字符串的前缀,那么我们称字符串 x 是 合法的 。
classSolution: defmaxScore(self, a: List[int], b: List[int]) -> int: n = len(b) @cache defdfs(i_b, idx_a): if idx_a == 4: return0 if n - i_b == 4 - idx_a: ans = 0 for i inrange(idx_a, 4): ans += a[i] * b[n-4+i] return ans take = dfs(i_b+1,idx_a+1) + a[idx_a] * b[i_b] ignore = dfs(i_b+1, idx_a) returnmax(take, ignore) ans = dfs(0,0) dfs.cache_clear() return ans
递推
1 2 3 4 5 6 7 8
classSolution: defmaxScore(self, a: List[int], b: List[int]) -> int: n = len(b) f = [0] + [-inf] * 4 for x in b: for i inrange(4, 0, -1): f[i] = max(f[i], f[i-1] + x * a[i-1]) return f[-1]
definsert(self, word: str) -> None: node = self for s in word: if s notin node.children: node.children[s] = Trie() node = node.children[s] node.isEnd = True defsearchPrefix(self, prefix: str) -> 'Trie': node = self for s in prefix: if s notin node.children: returnNone node = node.children[s] return node
# 保存每个 words[i] 的每个前缀的哈希值,按照长度分组 max_len = max(map(len, words)) sets = [set() for _ inrange(max_len)] for w in words: h = 0 for j, b inenumerate(w): h = (h * BASE + ord(b)) % MOD sets[j].add(h) # 注意 j 从 0 开始
ans = 0 cur_r = 0# 已建造的桥的右端点 nxt_r = 0# 下一座桥的右端点的最大值 for i inrange(n): check = lambda sz: sub_hash(i, i + sz + 1) notin sets[sz] sz = bisect_left(range(min(n - i, max_len)), True, key=check) nxt_r = max(nxt_r, i + sz) if i == cur_r: # 到达已建造的桥的右端点 if i == nxt_r: # 无论怎么造桥,都无法从 i 到 i+1 return -1 cur_r = nxt_r # 建造下一座桥 ans += 1 return ans
defput(self, s: str) -> None: cur = self.root for b in s: b = ord(b) - ord('a') if cur.son[b] isNone: cur.son[b] = Node(cur.len + 1) cur = cur.son[b]
defbuild_fail(self) -> None: self.root.fail = self.root q = deque() for i, son inenumerate(self.root.son): if son isNone: self.root.son[i] = self.root else: son.fail = self.root # 第一层的失配指针,都指向根节点 ∅ q.append(son) # BFS while q: cur = q.popleft() for i, son inenumerate(cur.son): if son isNone: # 虚拟子节点 cur.son[i],和 cur.fail.son[i] 是同一个 # 方便失配时直接跳到下一个可能匹配的位置(但不一定是某个 words[k] 的最后一个字母) cur.son[i] = cur.fail.son[i] continue son.fail = cur.fail.son[i] # 计算失配位置 q.append(son)
classSolution: defminValidStrings(self, words: List[str], target: str) -> int: ac = AhoCorasick() for w in words: ac.put(w) ac.build_fail()
n = len(target) f = [0] * (n + 1) cur = root = ac.root for i, c inenumerate(target, 1): # 如果没有匹配相当于移动到 fail 的 son[c] cur = cur.son[ord(c) - ord('a')] # 没有任何字符串的前缀与 target[..i] 的后缀匹配 if cur is root: return -1 f[i] = f[i - cur.len] + 1 return f[n]
classSolution: deffindSafeWalk(self, grid: List[List[int]], health: int) -> bool: m = len(grid) n = len(grid[0]) q = deque() q.append((health - grid[0][0],0,0)) visited = set() visited.add((0,0)) direction = [(1,0),(-1,0),(0,1),(0,-1)] while q: h, i, j = q.popleft() if i == m - 1and j == n - 1and h > 0: returnTrue for dx, dy in direction: new_x = i + dx new_y = j + dy if0 <= new_x < m and0 <= new_y < n and (new_x,new_y) notin visited and h > 0: if grid[new_x][new_y] == 1: q.append((h-1, new_x, new_y)) visited.add((new_x,new_y)) else: q.appendleft((h, new_x, new_y)) visited.add((new_x,new_y)) returnFalse
3287. 求出数组中最大序列值
给你一个整数数组 nums 和一个
正 整数 k 。
定义长度为 2 * x 的序列 seq 的
值 为:
(seq[0] OR seq[1] OR ... OR seq[x - 1]) XOR (seq[x] OR seq[x + 1] OR ... OR seq[2 * x - 1]).
请你求出 nums 中所有长度为 2 * k 的子序列的
最大值 。
示例 1:
输入:nums = [2,6,7], k = 1
输出:5
解释:
子序列 [2, 7] 的值最大,为 2 XOR 7 = 5 。
示例 2:
输入:nums = [4,2,5,6,7], k = 2
输出:2
解释:
子序列 [4, 5, 6, 7] 的值最大,为 (4 OR 5) XOR (6 OR 7) = 2 。
# https://leetcode.cn/problems/find-the-maximum-sequence-value-of-array/solutions/2917488/shai-xuan-pai-xu-dp-by-mipha-2022-9hr5 from copy import deepcopy classSolution: defmaxValue(self, nums: List[int], k: int) -> int: n = len(nums) # 第i位, 长j left = [ [set() for _ inrange(k+1)] for _ inrange(n+1)] left[0][0].add(0) for i inrange(n): # 不选 left[i+1] = deepcopy(left[i]) num = nums[i] # 选 for lj inrange(k): for lnum in left[i][lj]: left[i+1][lj+1].add(lnum|num)
right = [set() for _ inrange(k+1)] right[0].add(0) res = 0 for i inrange(n-1, -1, -1): tmp = deepcopy(right)
num = nums[i] for lj inrange(k): for lnum in right[lj]: tmp[lj+1].add(lnum|num) right = tmp
for a in left[i][k]: for b in right[k]: c = a ^ b if c > res: res = c return res
# https://leetcode.cn/problems/find-the-maximum-sequence-value-of-array/solutions/2917604/qian-hou-zhui-fen-jie-er-wei-0-1-bei-bao-8icz classSolution: defmaxValue(self, nums: List[int], k: int) -> int: n = len(nums) suf = [None] * (n-k+1) f = [set() for _ inrange(k+1)] f[0].add(0) for i inrange(n-1, k-1, -1): v = nums[i] for j inrange(min(k-1, n-1-i), -1, -1): f[j+1].update(x|v for x in f[j]) if i <= n - k: suf[i] = f[k].copy() mx = reduce(or_, nums) ans = 0 pre = [set() for _ inrange(k+1)] pre[0].add(0) for i, v inenumerate(nums[:-k]): for j inrange(min(k-1, i), -1, -1): pre[j+1].update(x | v for x in pre[j]) if i < k-1: continue ans = max(ans, max(x^y for x in pre[k] for y in suf[i+1])) if ans == mx: return ans return ans
3288. 最长上升路径的长度
给你一个长度为
n 的二维整数数组 coordinates 和一个整数 k ,其中 0 <= k < n 。
# https://leetcode.cn/problems/length-of-the-longest-increasing-path/solutions/2917590/pai-xu-lispythonjavacgo-by-endlesscheng-803g classSolution: defmaxPathLength(self, coordinates: List[List[int]], k: int) -> int: kx, ky = coordinates[k] coordinates.sort(key=lambda x:(x[0],-x[1])) g = [] for x, y in coordinates: if x < kx and y < ky or x > kx and y > ky: j = bisect_left(g, y) if j < len(g): g[j] = y else: g.append(y) returnlen(g) + 1
然后灵神出了一个思考题: 假设我们需要对所有k求解, 思路又是怎么样?
首先目前复杂度nlogn, 如果暴力的话复杂度就是n^2logn.
更简单的做法是前后缀的做法, 我们遍历坐标,
每次求出包含k号坐标的最长前缀LIS和后缀LIS.
对于前缀LIS, 我们bisect的结果其实就是答案,
后缀的话反转列表然后做最长递减子序列就好.
9月8周赛
3281. 范围内整数的最大得分
给你一个整数数组 start 和一个整数 d,代表
n 个区间 [start[i], start[i] + d]。
你需要选择 n 个整数,其中第 i
个整数必须属于第 i 个区间。所选整数的 得分
定义为所选整数两两之间的 最小 绝对差。
classSolution: defmaxPossibleScore(self, start: List[int], d: int) -> int: start.sort() defcheck(v): curr = start[0] for x in start[1:]: if curr + v < x: curr = x elif x <= curr + v <= x + d: curr = curr + v else: returnFalse returnTrue l = 0 r = start[-1] - start[0] + d while l <= r: mid = l + (r-l) // 2 if check(mid): l = mid + 1 else: r = mid - 1 return r
classSolution: deffindMaximumScore(self, nums: List[int]) -> int: n = len(nums) @cache defdfs(start): res = 0 for i inrange(start+1, n): if nums[i] > nums[start]: res = max(res, (i-start) * nums[start] + dfs(i)) if res == 0: return nums[start] * (n-1 - start) return res return dfs(0)
后面仔细思考了一下, 发现其实是个贪心:
永远选择比当前值更大的格子跳就行了.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: deffindMaximumScore(self, nums: List[int]) -> int: n = len(nums) curr_i = 0 curr_x = nums[0] ans = 0 for i, x inenumerate(nums[1:], start=1): if x > curr_x: ans += (i - curr_i) * curr_x curr_i = i curr_x = x if curr_i != n: ans += (n-1 - curr_i) * curr_x return ans
3283.
吃掉所有兵需要的最多移动次数
给你一个 50 x 50 的国际象棋棋盘,棋盘上有
一个 马和一些兵。给你两个整数 kx
和 ky ,其中 (kx, ky) 表示马所在的位置,同时还有一个二维数组 positions ,其中 positions[i] = [xi, yi] 表示第
i 个兵在棋盘上的位置。
classSolution: defmaxScore(self, grid: List[List[int]]) -> int: n = len(grid) # 每一行去重并降序排列 grid = list(map(lambda x: sorted(set(x))[::-1], grid)) # 每行最大值的前缀和 pre = list(accumulate([grid[i][0] for i inrange(n)])) ans = 0 # 已选的数 chosen = set()
# 现在决定第i行选谁,已选数的和为done defdfs(i, done): nonlocal ans if i == -1: if done > ans: ans = done return # 如果前i行都选最大值也不能超过ans,剪枝 if done + pre[i] <= ans: return for a in grid[i]: if a in chosen: continue chosen.add(a) dfs(i - 1, done + a) chosen.remove(a) # 当前行也可以不选 dfs(i - 1, done) dfs(n - 1, 0) return ans
状态压缩dp
先看我写的爆内存的版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: defmaxScore(self, grid: List[List[int]]) -> int: # bitset代表visited # i表示行 m = len(grid) n = len(grid[0]) @cache defdfs(i, visited): if i == m: return0 res = float('-inf') for j inrange(n): if (visited >> grid[i][j]) & 1 == 0: res = max(res, dfs(i+1, visited | (1<<grid[i][j])) + grid[i][j]) res = max(res, dfs(i+1, visited)) return res return dfs(0,0)
classSolution: defmaxScore(self, grid: List[List[int]]) -> int: d = defaultdict(set) max_ = 0 for i, row inenumerate(grid): for x in row: d[x].add(i) max_ = max(max_, x)
# i表示要选的数的大小 # j表示行数的bitmap @cache defdfs(i,j): if i == 0: return0 # 不选 res = dfs(i-1, j) # 选 for idx in d[i]: if1<<idx & j == 0: res = max(res, dfs(i-1, j | 1<<idx) + i) return res return dfs(max_, 0)
classSolution: defmaxScore(self, grid: List[List[int]]) -> int: d = defaultdict(set) max_ = 0 for i, row inenumerate(grid): for x in row: d[x].add(i) max_ = max(max_, x) n = 1<<len(grid) f = [0] * n for x, idx_set in d.items(): for j inrange(n): for k in idx_set: if j >> k & 1 == 0: f[j] = max(f[j],f[j|1<<k]+x) return f[0]
内存占用少很多
hack
scipy直接提供组优化工具, 非常巧妙
1 2 3 4 5 6 7 8 9 10 11 12 13
import numpy as np from scipy.optimize import linear_sum_assignment
arrays = np.array([[0for _ inrange(110)] for _ inrange(len(grid))])
for i, row inenumerate(grid): for cell in row: arrays[i][cell] = cell row_ind, col_ind = linear_sum_assignment(arrays, maximize=True) returnint(arrays[row_ind, col_ind].sum())
FAC = [1, 1] for i inrange(2, 15): FAC.append(FAC[-1] * i)
classSolution: defcountGoodIntegers(self, n: int, k: int) -> int: defctr_to_result(tpl): div_lst = [] exist_zero = False for k, v inenumerate(tpl): if k == 0: exist_zero = True div_lst.append(FAC[v]) ret = FAC[n] for group_div in div_lst: ret //= group_div
exclude = 0 div_lst = [] if exist_zero: exclude = FAC[n-1] for k, v inenumerate(tpl): if k == 0: div_lst.append(FAC[v-1]) else: div_lst.append(FAC[v]) for group_div in div_lst: exclude //= group_div return ret - exclude
# cons存counter res = 0 if n == 1: for i inrange(1, 10): if i % k == 0: res += 1 return res cons = set() if n % 2: # 12345 # mid -> 2 half = n // 2 upper = 10 ** (half) for i inrange(upper // 10, upper): for mid inrange(10): num = str(i) + str(mid) + str(i)[::-1] ifint(num) % k == 0: ctr = Counter(num) cons.add(tuple([ctr[str(i)] for i inrange(10)])) else: half = n // 2 upper = 10 ** (half) for i inrange(upper // 10, upper): num = str(i) + str(i)[::-1] ifint(num) % k == 0: ctr = Counter(num) cons.add(tuple([ctr[str(i)] for i inrange(10)]))
ans = 0 for ctr in cons: ans += ctr_to_result(ctr) return ans
classSolution: defcountGoodIntegers(self, n: int, k: int) -> int: v = (n + 1) // 2 vis = set() for x inrange(10 ** (v - 1), 10 ** v): ans = str(x) ans += ans[:n - len(ans)][::-1] ifint(ans) % k == 0: vis.add(tuple(sorted(Counter(ans).items()))) ans = 0 for x in vis: res = fac(n) for c, v in x: res //= fac(v) if x[0][0] == '0': val = fac(n - 1) val //= fac(x[0][1] - 1) for c, v in x[1:]: val //= fac(v) res -= val ans += res return ans
Q4. 对 Bob 造成的最少伤害
给你一个整数 power 和两个整数数组 damage
和 health ,两个数组的长度都为 n 。
Bob
有 n 个敌人,如果第 i 个敌人还活着(也就是健康值 health[i] > 0 的时候),每秒钟会对
Bob 造成 damage[i]点 伤害。
每一秒中,在敌人对 Bob 造成伤害 之后 ,Bob 会选择
一个 还活着的敌人进行攻击,该敌人的健康值减少
power 。
请你返回 Bob 将
所有n 个敌人都消灭之前,最少 会收到多少伤害。
示例 1:
输入:power = 4, damage = [1,2,3,4], health =
[4,5,6,8]
classSolution: defminDamage(self, power: int, damage: List[int], health: List[int]) -> int: # 打空health需要的turn固定 # 因此可以对怪物数据排序, 打死怪物之前会被怪物打多少 q = [] sum_ = sum(damage) health = [math.ceil(i/power) for i in health] for d, h inzip(damage, health): heapq.heappush(q, (-d/h, d, h)) ans = 0 while q: ratio, d, h = heapq.heappop(q) ans += sum_ * h sum_ -= d return ans
from sortedcontainers import SortedList classSolution: defgetFinalState(self, nums: List[int], k: int, multiplier: int) -> List[int]: mod_v = 10 ** 9 + 7 n = len(nums) if multiplier == 1: return nums if n == 1: return [(pow(multiplier, k, mod_v) * nums[0]) % mod_v] sorted_lst = SortedList(key=lambda x: (x[0], x[1])) for i inrange(n): sorted_lst.add([nums[i], i]) mul_lst = [0] * n while k and sorted_lst[0][0] * multiplier <= sorted_lst[-1][0]: x, idx = sorted_lst.pop(0) times = int(math.log(sorted_lst[0][0] / x, multiplier)) times = max(times, 1) k -= min(times, k) mul_lst[idx] += times sorted_lst.add([ x * pow(multiplier, times), idx])
div, mod = divmod(k, n) for x, i in sorted_lst: mul_lst[i] += div if mod: mul_lst[i] += 1 mod -= 1 d = {} for i inrange(n): if d.get(mul_lst[i]): nums[i] = int(nums[i] * d[mul_lst[i]]) % mod_v else: d[mul_lst[i]] = pow(multiplier, mul_lst[i], mod_v) nums[i] = int(nums[i] * d[mul_lst[i]]) % mod_v return nums
3267. 统计近似相等数对 II
注意:在这个问题中,操作次数增加为至多 两次 。
给你一个正整数数组 nums 。
如果我们执行以下操作
至多两次 可以让两个整数 x
和 y 相等,那么我们称这个数对是
近似相等 的:
选择 x或者y
之一,将这个数字中的两个数位交换。
请你返回 nums 中,下标 i 和
j 满足 i < j 且 nums[i]
和 nums[j]近似相等 的数对数目。
classSolution: defcountPairs(self, nums: List[int]) -> int: nums.sort(key=lambda x:len(str(x))) ctr = Counter() res = 0 for x in nums: s = str(x) lst = list(s) n = len(lst) visited = {x} for i inrange(n): for j inrange(i+1, n): lst[i], lst[j] = lst[j], lst[i] visited.add(int(''.join(lst))) for k inrange(i+1, n): for l inrange(k+1, n): lst[k], lst[l] = lst[l], lst[k] visited.add(int(''.join(lst))) lst[k], lst[l] = lst[l], lst[k]
lst[i], lst[j] = lst[j], lst[i] res += sum(ctr[x] for x in visited) ctr[x] += 1 return res
8月18双周赛
100401. 放三个车的价值之和最大
II
给你一个 m x n 的二维整数数组 board ,它表示一个国际象棋棋盘,其中 board[i][j] 表示格子
(i, j) 的 价值 。
classSolution: defmaximumValueSum(self, board: List[List[int]]) -> int: n, m = len(board), len(board[0]) all_nums = [(board[i][j], (i, j)) for i inrange(n) for j inrange(m)] all_nums.sort(reverse=True)
tot = 3 * max(n, m)
ans = -10**18 for start inrange(5): ai, aj = all_nums[start][1]
for i inrange(start + 1, tot): bi, bj = all_nums[i][1]
for j inrange(i + 1, tot): ci, cj = all_nums[j][1] if ai != bi and bi != ci and ai != ci and aj != bj and bj != cj and aj != cj: ans = max(ans, all_nums[start][0] + all_nums[i][0] + all_nums[j][0]) return ans
# https://leetcode.cn/problems/maximum-value-sum-by-placing-three-rooks-ii/solutions/2884186/qian-hou-zhui-fen-jie-pythonjavacgo-by-e-gc48 classSolution: defmaximumValueSum(self, board: List[List[int]]) -> int: defupdate(row: List[int]) -> None: for j, x inenumerate(row): if x > p[0][0]: if p[0][1] != j: # 如果相等,仅更新最大 if p[1][1] != j: # 如果相等,仅更新最大和次大 p[2] = p[1] p[1] = p[0] p[0] = (x, j) elif j != p[0][1] and x > p[1][0]: if p[1][1] != j: # 如果相等,仅更新次大 p[2] = p[1] p[1] = (x, j) elif j != p[0][1] and j != p[1][1] and x > p[2][0]: p[2] = (x, j)
m = len(board) suf = [None] * m p = [(-inf, -1)] * 3# 最大、次大、第三大 for i inrange(m - 1, 1, -1): update(board[i]) suf[i] = p[:]
ans = -inf p = [(-inf, -1)] * 3# 重置,计算 pre for i, row inenumerate(board[:-2]): update(row) for j2, y inenumerate(board[i + 1]): # 第二个车 for x, j1 in p: # 第一个车 for z, j3 in suf[i + 2]: # 第三个车 if j1 != j2 and j1 != j3 and j2 != j3: # 没有同列的车 ans = max(ans, x + y + z) # 注:手动 if 更快 break return ans
classSolution: deflargestPalindrome(self, n: int, k: int) -> str: pow10 = [1] * n for i inrange(1,n): pow10[i] = (pow10[i-1] * 10) % k count = n // 2 + (1if n % 2else0) ans = [None] * n # i 表示第i位 # j 表示余数为j @cache defdfs(i, j): if i == count: return j == 0 for d inrange(9, -1, -1): if n % 2and i == count - 1: new_j = (j + d * pow10[i]) % k else: new_j = (j + d * (pow10[i]+pow10[n-i-1])) % k if dfs(i+1, new_j): ans[i] = ans[n-i-1] = str(d) returnTrue returnFalse dfs(0,0) return''.join(ans)
100404. 统计满足 K
约束的子字符串数量 II
给你一个 二进制 字符串 s 和一个整数
k。
另给你一个二维整数数组 queries ,其中
queries[i] = [li, ri] 。
如果一个 二进制字符串
满足以下任一条件,则认为该字符串满足 k 约束:
字符串中 0 的数量最多为 k。
字符串中 1 的数量最多为 k。
返回一个整数数组 answer ,其中 answer[i]
表示 s[li..ri] 中满足 k 约束
的子字符串的数量。
classSolution: defcountKConstraintSubstrings(self, s: str, k: int, queries: List[List[int]]) -> List[int]: left = [] count = [0, 0] l = 0 for i in s: count[ord(i)&1] += 1 while count[0] > k and count[1] > k: count[ord(s[l])&1] -= 1 l += 1 left.append(l)
prefix_left = list(accumulate(left)) ans = [] for l, r in queries: base = (r + l + 2) * (r-l+1) // 2 idx = bisect.bisect_left(left, l+1) - 1 # left[idx] < l # left[idx+1] > l if idx > r: neg = l * (r-l+1) elif idx < l: neg = prefix_left[r] - prefix_left[l-1] else: neg = prefix_left[r] - prefix_left[idx] + l * (idx-l+1) ans.append(base - neg) return ans
8月11周赛
100354. 统计好节点的数目
现有一棵 无向 树,树中包含 n
个节点,按从 0 到 n - 1 标记。树的根节点是节点
0 。给你一个长度为 n - 1 的二维整数数组
edges,其中 edges[i] = [ai, bi] 表示树中节点
ai 与节点 bi 之间存在一条边。
classSolution: defcountGoodNodes(self, edges: List[List[int]]) -> int: n = len(edges) + 1 graph = [[] for i inrange(n)]
for u, v in edges: graph[u].append(v) graph[v].append(u)
ans = 0 defdfs(curr, parent): total = 1 prev = 0 found = True for node in graph[curr]: if node != parent: size = dfs(node, curr) if prev > 0and prev != size: found = False prev = size total += size nonlocal ans ans += found return total dfs(0,-1) return ans
classSolution: defshortestDistanceAfterQueries(self, n: int, queries: List[List[int]]) -> List[int]: g = [[] for _ inrange(n)] for i inrange(n-1): g[i].append(i+1) defdijkstra(g): ans = [float('inf')] * n q = [(0,0)] while q: w, v = heapq.heappop(q) if w > ans[v]: continue for node in g[v]: if ans[node] > 1 + w: ans[node] = 1 + w heapq.heappush(q, [1+w, node]) return ans[-1] ans = [0] * len(queries) for i, (u, v) inenumerate(queries): g[u].append(v) ans[i] = dijkstra(g) return ans
100376. 新增道路查询后的最短距离
II
给你一个整数 n 和一个二维整数数组
queries。
有 n 个城市,编号从 0 到
n - 1。初始时,每个城市 i
都有一条单向道路通往城市 i + 1(
0 <= i < n - 1)。
queries[i] = [ui, vi] 表示新建一条从城市 ui
到城市 vi
的单向道路。每次查询后,你需要找到从城市 0
到城市 n - 1
的最短路径的长度。
defEratosthenes(self, n: int) -> List[int]: is_prime = [True] * (n+1) is_prime[0] = is_prime[1] = False prime = [] for i inrange(n+1): if is_prime[i]: prime.append(i) curr = i * i while curr <= n: is_prime[curr] = False curr += i return prime
defEuler(self, n: int) -> List[int]: is_prime = [True] * (n+1) is_prime[0] = is_prime[1] = False prime = [] for i inrange(n+1): if is_prime[i]: prime.append(i) for p in prime: if p * i > n: break is_prime[p*i] = False if i % p == 0: break return prime
前缀和和切片
1 2 3 4 5 6 7 8
MAX = isqrt(10 ** 9) + 1 pi = [0] * (MAX + 1) for i inrange(2, MAX+1): if pi[i] == 0: pi[i] = pi[i-1] + 1 pi[i*i::i] = [-1] * ((MAX - i*i) // i + 1) else: pi[i] = pi[i-1]
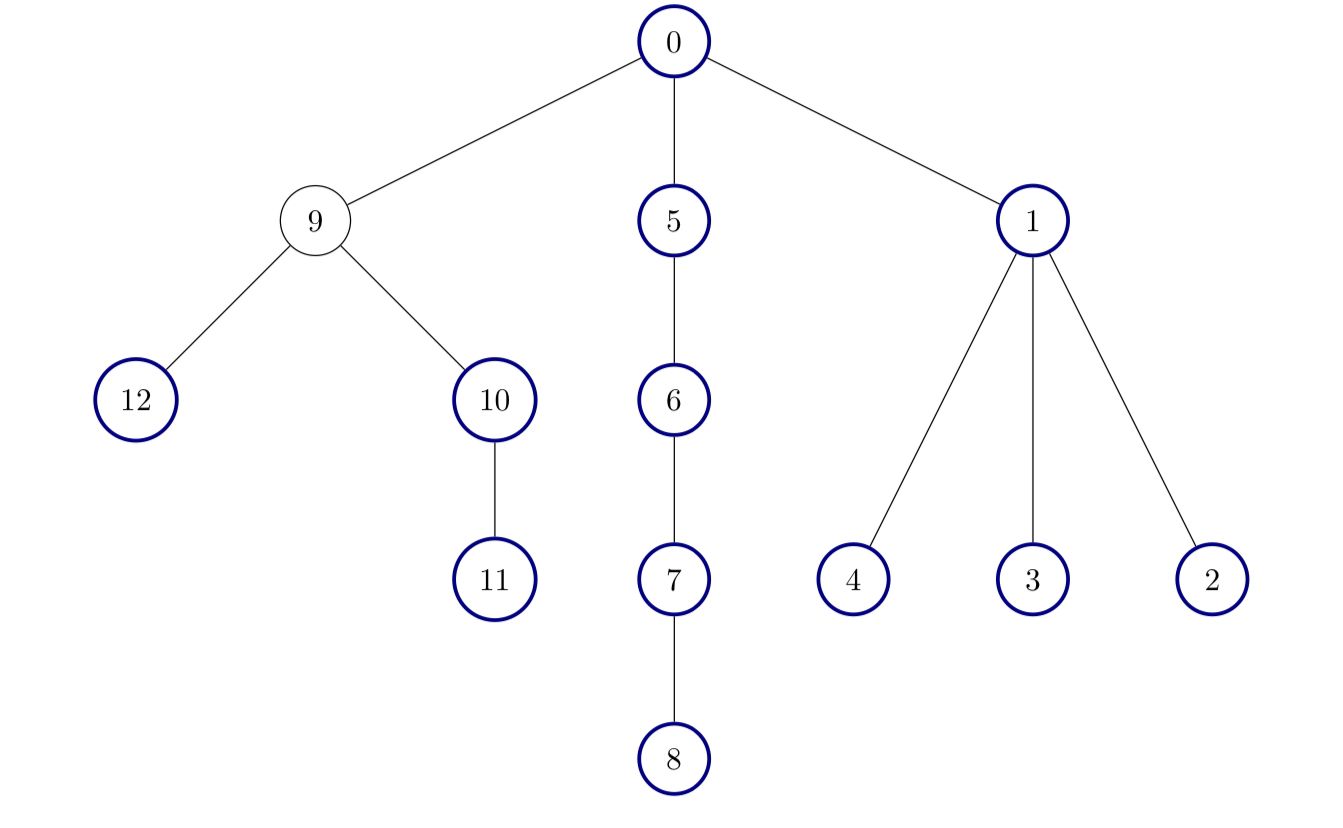
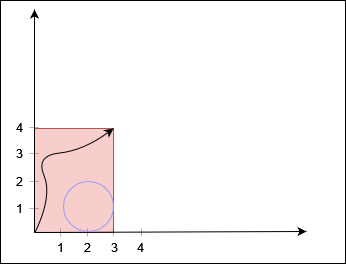
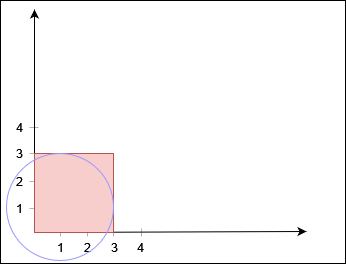
classSolution: defcanReachCorner(self, x: int, y: int, a: List[List[int]]) -> bool: n = len(a) # 并查集中的 n 表示左边界或上边界,n+1 表示下边界或右边界 fa = list(range(n + 2)) # 非递归并查集 deffind(x: int) -> int: rt = x while fa[rt] != rt: rt = fa[rt] while fa[x] != rt: fa[x], x = rt, fa[x] return rt defmerge(x: int, y: int) -> None: fa[find(x)] = find(y)
for i, (ox, oy, r) inenumerate(a): if ox <= r or oy + r >= y: # 圆 i 和左边界或上边界有交集 merge(i, n) if oy <= r or ox + r >= x: # 圆 i 和下边界或右边界有交集 merge(i, n + 1) for j, (qx, qy, qr) inenumerate(a[:i]): if (ox - qx) * (ox - qx) + (oy - qy) * (oy - qy) <= (r + qr) * (r + qr): merge(i, j) # 圆 i 和圆 j 有交集 if find(n) == find(n + 1): # 无法到达终点 returnFalse returnTrue
classSolution: defcanReachCorner(self, X: int, Y: int, circles: List[List[int]]) -> bool: n = len(circles) vis = [False] * n q = deque() for i, (x, y, r) inenumerate(circles): if y + r >= Y or x - r <= 0: vis[i] = True q.append(i) whilelen(q) > 0: j = q.popleft() xj, yj, rj = circles[j] if xj + rj >= X or yj - rj <= 0: returnFalse for i, (x, y, r) inenumerate(circles): if (not vis[i]) and (xj - x) ** 2 + (yj - y) ** 2 <= (r + rj) ** 2: vis[i] = True q.append(i) returnTrue